Hbase快速数据导入工具BulkLoad:利用Hbase的数据以特定的格式存储在HDFS内这一原理,通过MapReduce作业直接生成这种数据格式文件,然后上传到HDFS上合适的位置,完成大量数据快速入库。
Hbase数据带入方式
- HBase Client 调用方式
- MapReduce 任务方式
- BulkLoad 工具方式
- Sqoop 工具方式
BulkLoad优劣势
优势
- 如果一次性入导入Hbase表的数据量巨大,不仅处理速度慢不说,还特别占用Region资源, 一个比较高效便捷的方法就是使用 “Bulk Loading”方法,即HBase提供的HFileOutputFormat类。
- 利用Hbase的数据以特定的格式存储在HDFS内这一原理,直接生成这种HDFS中存储的数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载。
劣势
- 仅适合初次数据导入,即表内数据为空。
- HBase集群与Hadoop集群为同一集群,即HBase所基于的HDFS为生成HFile的MR的集群。
BulkLoad使用
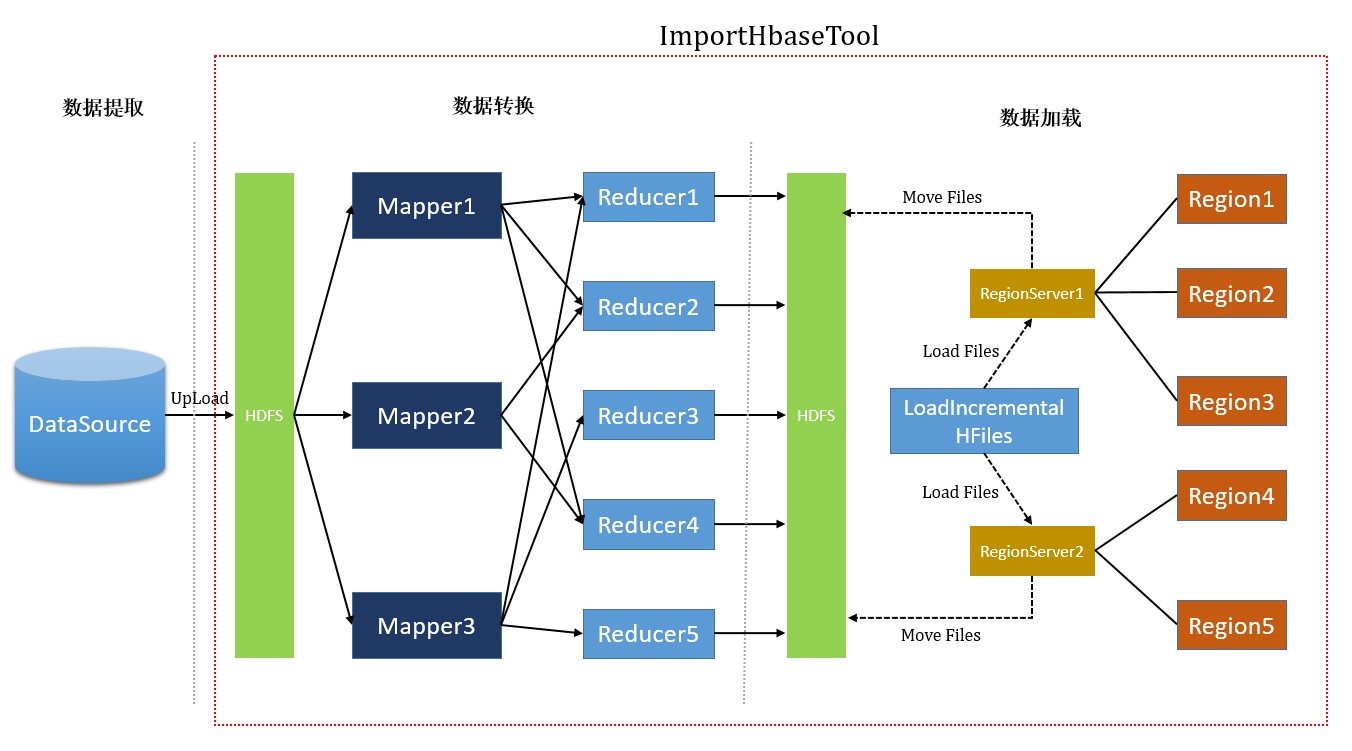
- 从数据源(通常为文本文件或其它数据库)提取数据并上传到HDFS。
- 利用一个MapReduce作业准备数据:通过编排一个MapReduce作业,需手动编写map函数,作业需要使用rowkey(行键)作为输出Key,KeyValue、Put或者Delete作为输出Value。MapReduce作业需要使用Hbase提供的HFileOutputFormat2来生成Hbase底层存储的HFile数据格式文件。为了有效的导入数据,需要配置HFileOutputFormat2使得每一个输出文件都在一个合适的区域中。
- 告诉RegionServers数据的位置并导入数据,这一步需要使用Hbase中的LoadIncrementalHFiles,将文件在HDFS上的位置传递给它,它就会利用RegionServer将数据导入到相应的区域,完成与Hbase表的关联。
命令行导入
直接导入数据
在Hbase中创建空表,如userinfo,使用Hbase自带的ImportTsv工具导入/opt/userinfo.tsv数据文件
|
|
分步导入数据
- 将userinfo.tsv文件上传到HDFS某个目录,并在Hbase中创建userinfo表
|
|
- 利用ImportTsv工具的Dimporttsv.bulk.output参数项指定生成的HFile文件位置/date_dir/bulkload_data/output
|
|
- 利用completebulkload完成bluk load数据导入
|
|
相关说明
- 将数据文件生成HFile方式是所有的加载方案里面是最快的,前提是:Hbase表须为空!如果表中已经有数据,HFile再次导入的时候,HBase的表会触发split分割操作
- 最终输出结果,无论是Map还是Reduce,输出建议只使用
- 指定的列和源文件字段必须全部匹配,不匹配则一定导入失败
- 命令行导入时默认的分隔符为tab符
- RowKey可以在任何位置:
假设存在数据4列(逗号为分隔符)
1,2,3,4
第一列RowKey
RowKey,2,3,4
第三列RowKey
1,2,RowKey,4 - 常用参数说明:
-Dimporttsv.skip.bad.lines=false –> 若遇到无效行则失败
‘-Dimporttsv.separator=|’或‘-Dimporttsv.separator=,’ –> 指定分割符
-Dimporttsv.timestamp=currentTimeAsLong –> 导入时使用指定的时间戳
-Dimporttsv.mapper.class=my.Mapper –> 使用用户指定的Mapper类(默认的org.apache.hadoop.hbase.mapreduce.TsvImporterMapper)
参考链接
http://www.ibm.com/developerworks/cn/opensource/os-cn-data-import/index.html
http://www.aboutyun.com/thread-11652-1-1.html
