Hue作为一个能与Hadoop集群进行交互的Web UI,大大降低了用户对某些大数据组件的操作使用成本。本文通过一些简单实例来介绍Hue中某些组件的使用,如Oozie任务调度,Hbase BulkLoad数据导入,Pig数据加载等
Oozie任务调度
MapReduce任务
说明:本例使用Hadoop自带的jar包中的WordCount任务,操作用户:admin
1.上传hadoop自带的jar包到HDFS上(这里上传到/user/admin/MapReduceJob目录下)
2.使用Hue中Workflow编辑器,添加Mapreduce任务,并做如下配置,如图:

propersities具体配置信息:
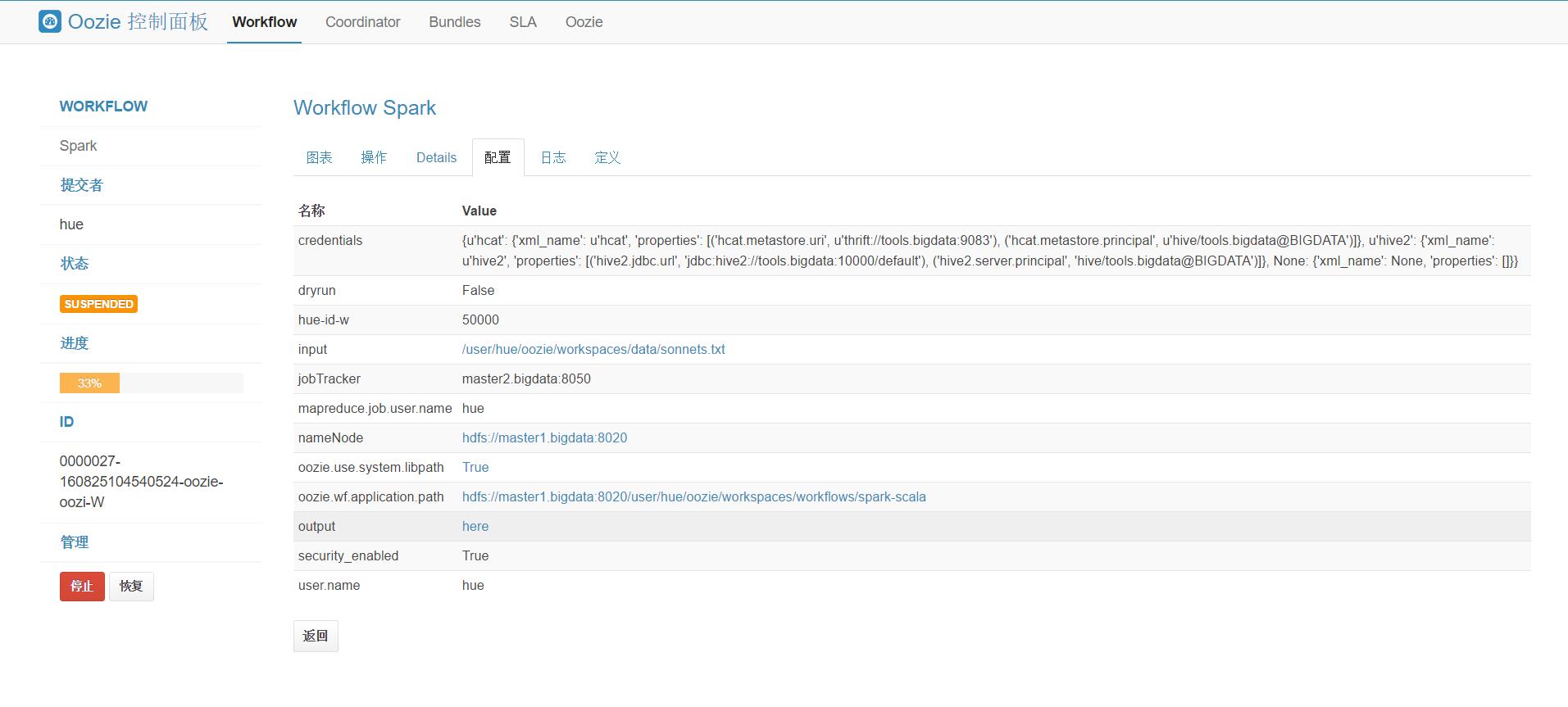
3.在Coordinator和Bundles页面给任务做更多的设置,如设置任务执行时间,绑定多个任务等。点击保存并提交任务,在Oozie的仪表盘和Yarn任务管理页面查看任务状态。
Spark任务
说明:本例测试使用Hue提供的SparkFileCopy任务,操作用户:admin
1.上传jar包到HDFS某个目录
2.使用Hue中Workflow编辑器,添加Spark任务,并做如下配置,如图:
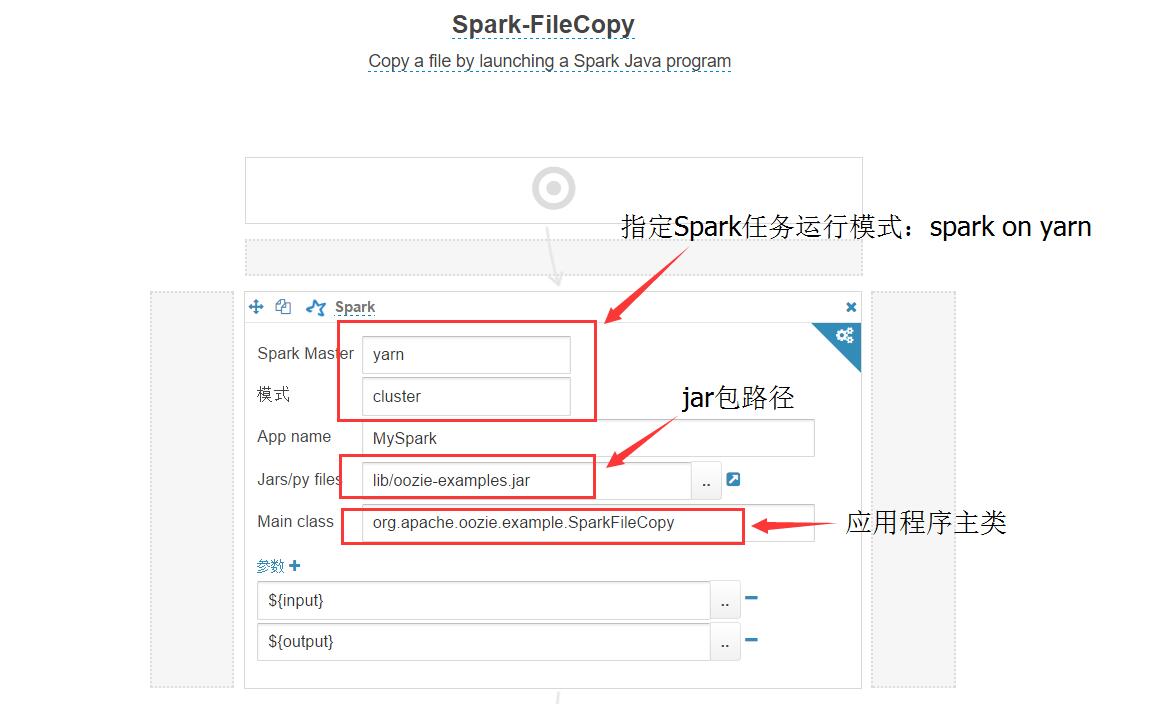
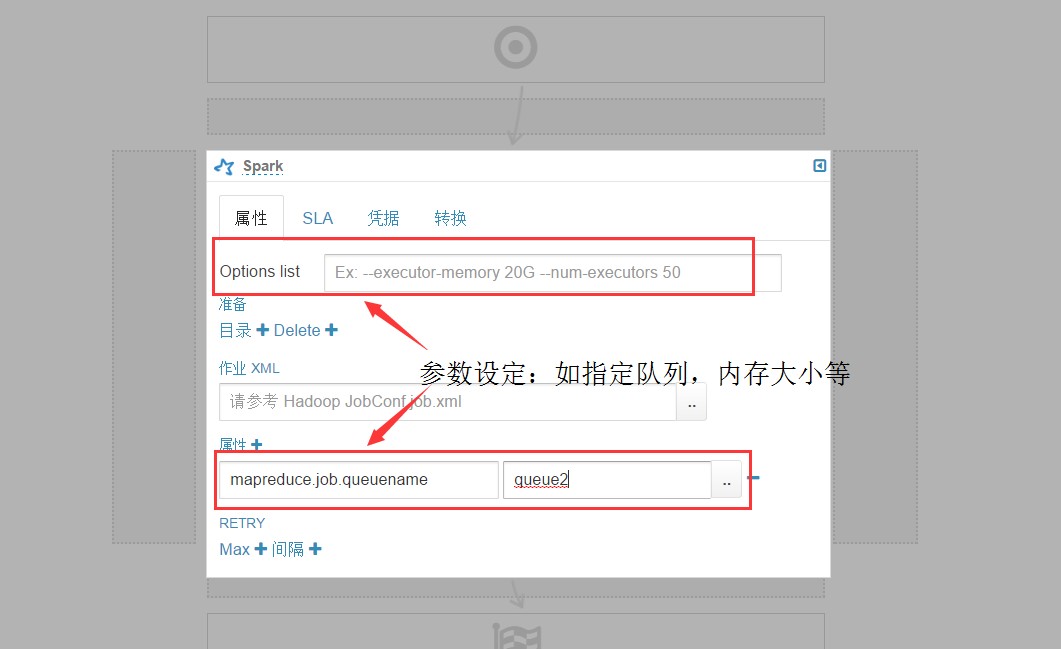
3.保存并提交任务,在Oozie的仪表盘和Yarn任务管理页面查看任务状态。
Hbase数据导入
BulkLoad数据导入
1.在Hue的Hbase模块新建表:userinfo,两个列族:info和grade
2.在Windows本地某一目录新建数据文件:userinfo.csv,文件内容如下图
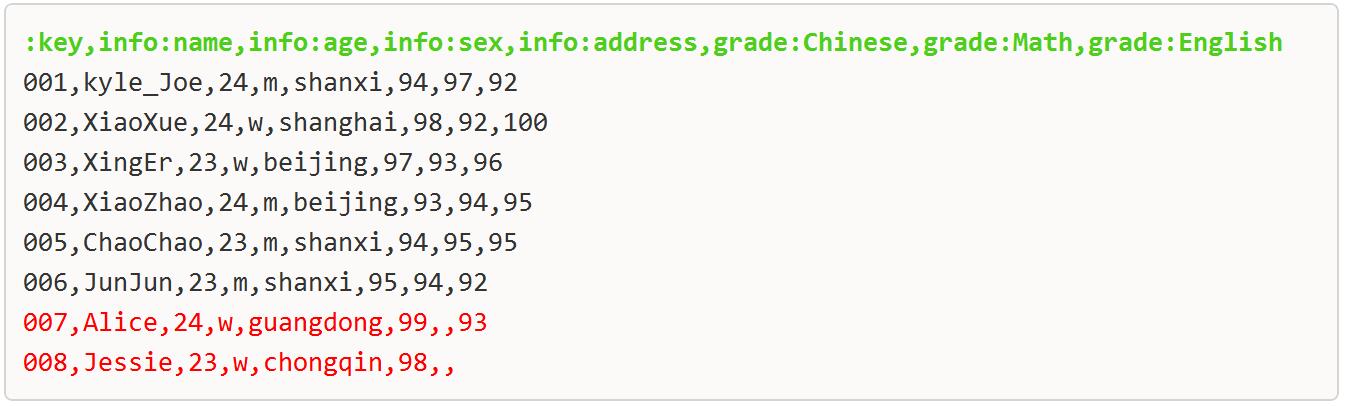
说明:
1)导入的文件中每行数据数量必须匹配对应的行数,数据可以不存在,但必须用对应的分隔符留出该字段位置。
2)因bulkload不支持多个分隔符划分字段,数据文件第一行每个列之间注意用单个分隔符分割,且不要留空格。
3.在Hue的Hbase模块打开userinfo表,点击BulkLoad加载本地数据文件userinfo.csv,数据导入成功
Pig数据加载
Hue提供的Pig应用允许用户定义pig脚本、运行脚本、以及查看Job的工作状态。执行的Pig脚本会自动由Oozie提交到Yarn任务管理器上,所以在Oozie仪表盘以及Yarn任务管理都能看到此Pig任务的运行状态。可以看出在Hue中Pig的使用依赖Oozie。
1.在HDFS的某目录下(这里使用/user/admin/PigTestData目录)创建数据文件student.txt
student.txt数据文件内容:
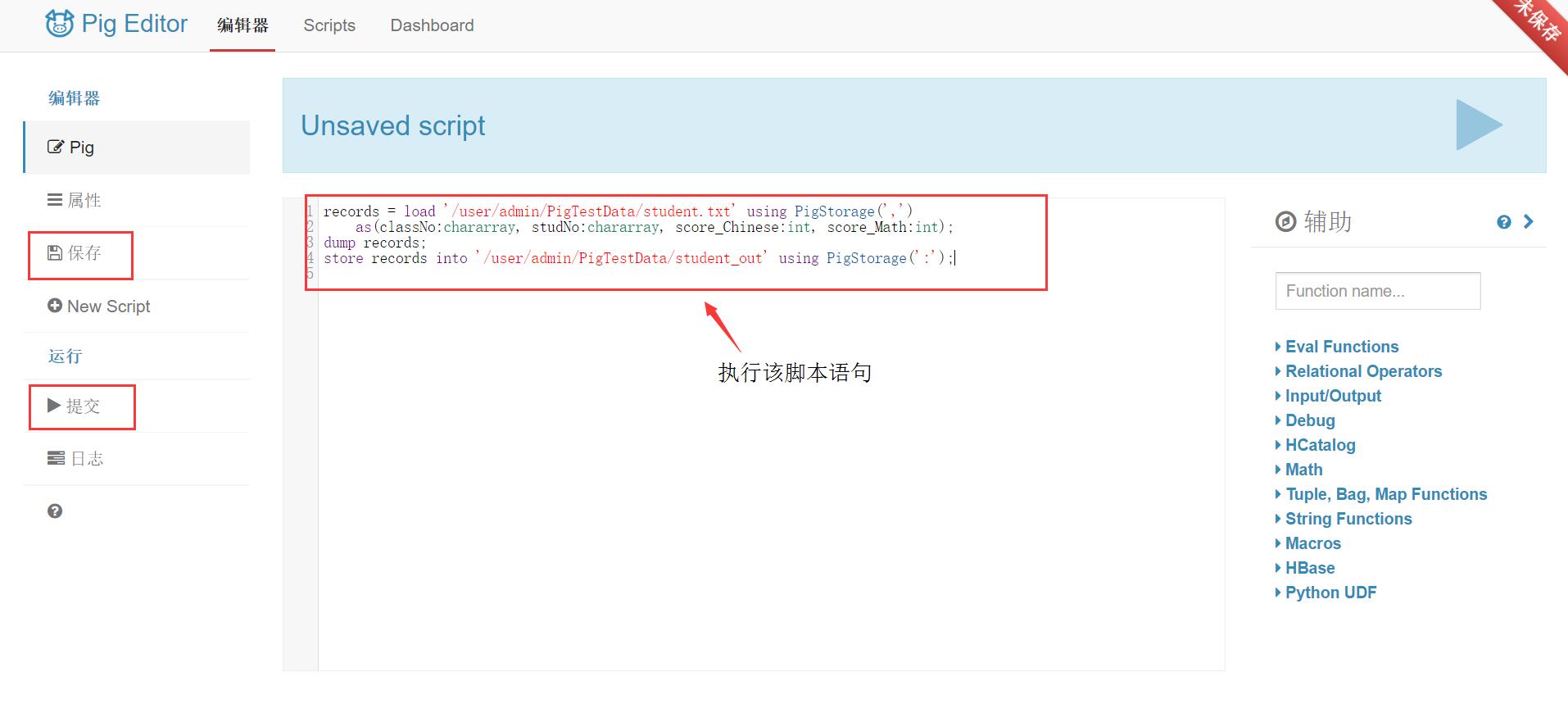
Pig脚本语句:
2.在Hue的Pig模块执行如下Pig脚本,内容如下图